Auf dieser Seite präsentieren wir Ihnen Egebnisse aus dem Projekt StaRQ zu Big Data und Genderkompetenz bzw. Geschlechter-/ Gendersensibilisierung. Im Rahmen des vom BMBF geförderten Projekts arbeitet ein interdisziplinäres Team mit Expertise in Computational Social Sciences sowie Geschlechter- und Hochschulforschung abteilungsübergreifend an der Analyse von Gleichstellungsmaßnahmen in der Wissenschaft. Der German Academic Web (GAW) Crawl dient dabei als Datengrundlage für verschiedene Fragestellungen. Ziel der hier dargestellten Untersuchung ist ein Vergleich zwischen Theorie und Praxis bzgl. der Aktivitäten der Hochschulen zu Gendersensibilisierung. Das Thema ist in den letzten Jahren stärker in den Fokus gerückt im Zusammenhang mit den Voraussetzungen für eine nachhaltige Transformation der Hochschulen („fix the knowledge“). Hierdurch werden neben den Gleichstellungsakteur*innen und den Lehrenden auch weitere Zielgruppen in den Blick genommen, insbesondere Personen mit Leitungsfunktionen und Beteiligte an Berufungsverfahren. Die Analyse zielt zum einen darauf ab, Transparenz zu erreichen über Maßnahmen zur Vermittlung von Gendersensibilisierung. Zum anderen standen die Zielgruppen dieser Maßnahmen im Fokus.
Im Folgenden verwenden wir den Begriff Gendersensibilisierung, da dies zum einen der Zielsetzung der Maßnahmen besser entspricht und zum anderen sich der Begriff im Hochschulkontext etabliert hat. Seit 2015 werden die Begriffe Gendersensibilität, gendersensibel und Gendersensibilisierung häufiger als Genderkompetenz auf Hochschulseiten verwendet.
Der German Academic Web (GAW) Crawl ist ein halbjährlich erhobenes Web-Archiv. Seit 2014 werden hierbei auf Basis einer Seedlist von URLs deutscher Universitäten mit Promotionsrecht (vgl. „Liste der Hochschulen in Deutschland“, Wikipedia) erstellt. Mit diesen Seiten als Startpunkt werden rekursiv weitere URLs erkannt und archiviert. Am Ende des ca. zweiwöchigen Prozesses sind ca. 100 Millionen Seiten und dazugehörige Metadaten pro Halbjahr gespeichert. Die Metadaten bestehen unter anderen aus dem Zeitpunkt des Ladens und einem eindeutigen Identifier.
Abbildung 1: Standorte der Hochschulen in Deutschland, von denen Webseiten im GAW Crawl archiviert wurden. (vgl. https://german-academic-web.de/map.html, abgerufen am 28.06.2022)
Ziel war es herauszufinden, welche konkreten Veranstaltungen an den Hochschulen zu Gendersensibilisierung angeboten werden und welche Zielgruppen hierdurch adressiert werden. Methodisch wählte das StaRQ-Projektteam eine Kombination aus Bottom-Up- und Top-Down-Analyse.
GAW Crawl: Teil-Korpora
Um einen thematischen Einblick in die gecrawlten Webseiten zu erhalten, wurde eine Top-Down-Analyse für verschiedene Fragestellungen erstellt. Top-Down bedeutet hier, dass für die Analyse im gesamten Korpus nach relevanten Seiten gesucht wurde. Diese wurden darauffolgend auf thematische Zusammenhänge untersucht, um herauszufinden, welche weiteren Themen für die Beantwortung von Fragestellungen von Interesse sein könnten. Dieser Prozess ermöglicht einen Kompromiss aus Vorauswahl und Ergebnisoffenheit bei dem Auffinden verwandter thematischer Zusammenhänge.
Die größte technische Herausforderung ist der immense Umfang der archivierten Webseiten. Um den GAW Crawl für eine thematische Analyse handhabbar zu machen, wurde deshalb eine Vorauswahl durch an die Fragestellungen angepasste Wortlisten (Filterterme) erstellt. Bei der Erstellung der Teil-Korpora wurden nun nur diejenigen Webseiten als Grundlage genutzt, bei denen einer der Begriffe auftauchte. Mithilfe von regulären Ausdrücken wurden die Schreibweisen der Filterterme vor der Suche generalisiert, damit konnte die Anzahl der gefundenen Webseiten erhöht werden.
Die nachfolgende Tabelle gibt einen Überblick über die im Projekt erstellten Teil-Korpora des GAW Crawls, die jeweils unterschiedliche Fragestellung im Projekt abbilden.
Teil-Korpus | Zeitspanne | Scope (#Webseiten) | Filterterme |
GAW-StaRQ-Recruitment | 2019 | 2.733 | Berufungs*, Headhunting*, etc. + Gleichstellung*, etc. |
GAW-StaRQ-Mentoring | 2015-2021 | 10.249 | Mentor*, Mentee*, etc. |
GAW-StaRQ-Gender Sensitivity | 2015-2021 | 1.800 | genderkompeten*, gendersensib*, geschlechterkompeten*, geschlechtersensib* |
GAW-StaRQ-Non-Binary | 2015-2021 | 690 | transgeschlecht*, nicht-binär*, etc. |
Tabelle 1: Kennzahlen der erstellten Teil-Korpora im Zeitraum 2015-2021. Der Umfang variiert hierbei in Abhängigkeit von den zur Filterung genutzten Termen sowie die Auswahl der zu untersuchenden Zeitspanne. Terme mit Asterisk (*) wurden hier mit Hilfe von regulären Ausdrücken generalisiert. Die Zeitspanne definiert, wie viele Zeitscheiben des GAW Crawls untersucht werden sollen.
Analyse des Gendersensibilisierungs-Korpus
1. Schritt | Top-Down-Analyse: Topic Modeling
Zu Beginn der Analyse wurde untersucht, welche thematischen Zusammenhänge in dem erstellten Teil-Korpus Gendersensibilisierung identifiziert werden können. Dafür wurde ein Topic Modeling (vgl. archivierte Version des Original-Artikels) durchgeführt. Dieses ist in der Lage, aufgrund einer Modellierung mit Hilfe bayesscher Statistik in einem unüberwachten Verfahren für jedes Dokument eine Verteilung von Themenclustern (Topics) zu ermitteln. Das bedeutet, zu wieviel Prozent die auf der Webseite verwendeten Wörter einzelnen gefundenen Topics im gesamten Teil-Korpus zugeordnet werden können. Diese Topics wiederum werden aufgrund der in den einzelnen Webseiten zugeordneten Wörter charakterisiert. Diese Charakterisierung ist also eine Verteilung der besonders häufig gemeinsam vorkommenden Begriffe innerhalb eines Topics. Ein Beispiel hierfür sind die in Abbildung 2 gezeigten Terme, durch die das Topic „Bildungsveranstaltungen“ beschrieben wird. Solche zusammenfassenden Namen wurden von Mitgliedern des StaRQ-Teams mit Gender-Expertise für die Topics gewählt.
In dem Teil-Korpus Gendersensibilisierung wurden acht Topics identifiziert. Als relevant für den Praxisvergleich schätzten die Gender-Expert*innen im Team die folgenden Topics ein: „Sprache und Literatur“, „Studium und Lehre“ sowie „Bildungsveranstaltungen“. Diese drei Topics wurden für weitere Analysen gewählt, wobei an dieser Stelle exemplarisch die weiteren Recherchen zum Thema Bildungsveranstaltungen beschrieben werden.
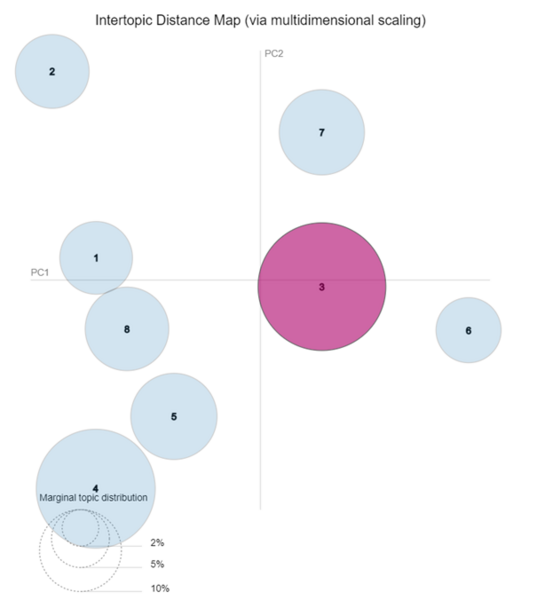
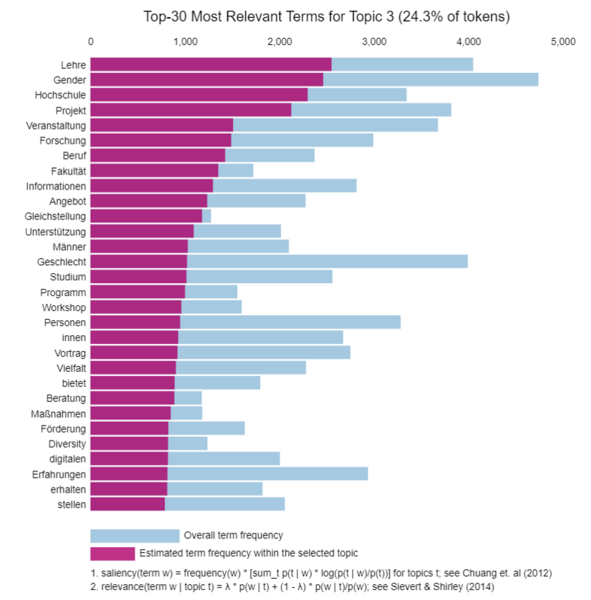
Abbildung 2: Die zweidimensionale Darstellung der acht mit Hilfe eines Topic Modelings gefundenen Themenschwerpunkte im Teil-Korpus „Gendersensibilisierung“.
Die Distanz in der Anordnung spiegelt die inhaltliche Ähnlichkeit wider. Die eine Wortliste charakterisiert das ausgewählte Topic 3. Hierbei beschreibt der magentafarbene Balken die Wahrscheinlichkeit, dass ein Wort in dem Topic zugeordneten Dokumenten vorhanden ist. Der blaue Balken gibt einen Hinweis wie oft ein Begriff im gesamten Teilkorpus auftaucht. Je länger der Balken, desto allgemeiner ist der Begriff.
2. Schritt | Thematische Bottom-Up-Analyse zu Bildungsveranstaltungen
Die Topic-Analyse hat Bildungsveranstaltungen als Untersuchungsgegenstand identifiziert, der mit Hilfe des Gendersensibilisierungs-Korpus‘ weiter untersucht werden sollte. Genauer gesagt sollten Bildungsveranstaltungen zur Vermittlung von Gendersensibilität identifiziert werden und in einer Bottom-Up-Analyse die konkreten Nennungen anhand der Seiten, auf denen sie gefunden wurden, erhoben werden. Insbesondere bestand die Frage, ob mithilfe dieses Verfahrens und den Daten des GAW Crawls relevante Bildungsveranstaltungen zum Thema erhoben werden können.
Zu Beginn wurde eine Liste von Namen zur Identifizierung von Bildungsveranstaltungen erstellt. Neben dem Fachwissen des Projektteams wurde zusätzlich auf automatisch erstellte Vorschläge zurückgegriffen. Dafür wurden initiale Namen von Bildungsveranstaltungen gewählt (z.B. Vorlesung, Seminar, Tagung). Dann wurden durch ein erstelltes Word-Embedding-Modell automatisch ähnliche Wörter vorgeschlagen. Insgesamt konnten mit diesem semi-automatischen Verfahren 80 relevante Begriffe aus vier manuell erstellten Kategorien identifiziert werden.
Diese vier identifizierten Kategorien wurden genutzt, um die 80 Begriffe zu clustern:
- Lehrveranstaltungen (Vorlesungen etc.)
- Personalentwicklung und Nachwuchsförderung (Workshops, Weiterbildungen etc.)
- wissenschaftliche Veranstaltungen (Konferenzen etc.)
- Zertifikate
Für eine detaillierte Analyse wurde exemplarisch die Kategorie Personalentwicklung und Nachwuchsförderung mit den prominentesten Unterkategorien Workshops, Weiterbildungen, Fortbildungen und Trainings zu Gendersensibilität im entsprechenden Teil-Korpus untersucht. Hierfür wurden alle gefundenen Sätze im Teil-Korpus Gendersensibilisierung analysiert. Befand sich in einem Satz ein Wort der Unterkategorien Workshops, Weiterbildungen, Fortbildungen oder Trainings und im gleichen Satz eine Nennung von Gendersensibilität (ähnliche Schreibweisen und Wortstämme wurden inkludiert), wurde der Satz automatisch in die Analysedatenbasis einbezogen.
Im Folgenden wurden die 136 Satz-Fundstellen auf den Webseiten näher untersucht und annotiert. Hier wurde also ein kombinierter Ansatz aus automatisierter Suche und manueller Überprüfung und Codierung gewählt. Als relevant wurde eine Satz-Fundstelle erachtet, wenn es sich um Veranstaltungen im Bereich Personalentwicklung und Nachwuchsförderung zu Gendersensibilisierung von und/oder für Mitglieder der Hochschule handelte. Die Unterkategorie Workshops hatte mit 84 Satz-Fundstellen die höchste Trefferzahl und zeigte eine hohe Relevanz: Nur eine Satz-Fundstelle wurde als inhaltlich nicht relevant erachtet.
Da es vorkommen kann, dass mehrere gefundene Sätze den gleichen Workshop referenzieren, ergab die Analyse 74 identifizierte Workshop-Bezüge. In fünf Fällen handelte es sich bei zwei unterschiedlichen Sätzen um Erläuterungen desselben Workshops. In weiteren fünf Fällen handelte es sich um nahezu gleiche Sätze (Naheduplikate), die von den gleichen URLs zu unterschiedlichen Zeitpunkten extrahiert wurden. Da in diesen Fällen die Sätze nicht exakt gleich waren, wurden sie als unterschiedliche Satz-Fundstellen gezählt (Siehe Beispiel 1). Allerdings referenzierten auch diese Fundstellen den gleichen Workshop.
Beispiel 1: Naheduplikat:
„Darüber hinaus werden die Mentees ermuntert, innerhalb der Förderphase an Workshops zur Gendersensibilisierung (fakultätsübergreifend organisiert) teilzunehmen.“
„Darüber hinaus werden die Mentees ermuntert, innerhalb der zweijährigen Förderphase an (fakultätsübergreifend organisierten) Workshops zur Gendersensibilisierung teilzunehmen.“
Die gefundenen Nennungen im Bespiel stammen von einer Webseite, die zu verschiedenen Zeitpunkten gecrawlt wurden. In der Zwischenzeit wurde sie an den kursiv hervorgehobenen Stellen editiert.
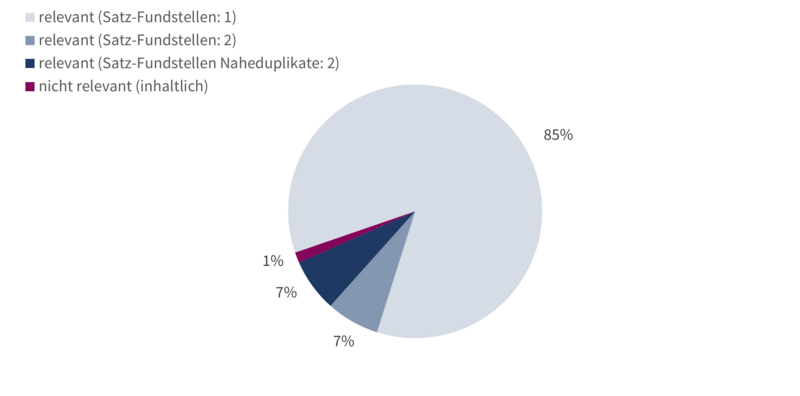
Abbildung 3: Workshop-Fundstellen auf Hochschul-Webseiten mit Gendersensibilisierungs-Bezug im Gendersensibilisierungs-Korpus. Workshops können aufgrund mehrerer Satz-Fundstellen annotiert sein. Ein Sonderfall sind Satz-Fundstellen, die zu unterschiedlichen Zeitpunkten in leicht editierten Versionen im Korpus enthalten sind (Satz-Fundstellen Naheduplikate: Siehe Beispiel 1) (n = 74 Workshops)
Aufgrund der zahlreichen Satz-Fundstellen und der hohen Relevanz wurde für eine tiefergehende Analyse exemplarisch die Unterkategorie Workshops ausgewählt. Hierzu wurden die relevanten Fundstellen in Hinblick auf die in den Workshop beschriebenen Zielgruppen annotiert. Die Zielgruppen wurden zur Analyse in sechs Gruppen eingeteilt. Hierbei orientierte sich das Projektteam an den Workshop-Beschreibungen auf den Webseiten. Zielgruppen außerhalb von Hochschulen wie etwa Schüler*innen oder Lehrkräfte an Schulen wurden nicht in die Analyse mit einbezogen. Insofern ergab sich eine neue reduzierte Grundgesamtheit an relevanten Workshops bzgl. hochschulinterner Zielgruppen (n = 60). Die folgende Grafik (Abbildung 4) zeigt die Verteilung der identifizierten Zielgruppen auf die Workshops (Mehrfachnennungen möglich).

Abbildung 4: Verteilung der Zielgruppen innerhalb der Hochschulen auf Workshops
Zusammenfassend lässt sich der Prozess wie folgt beschreiben:
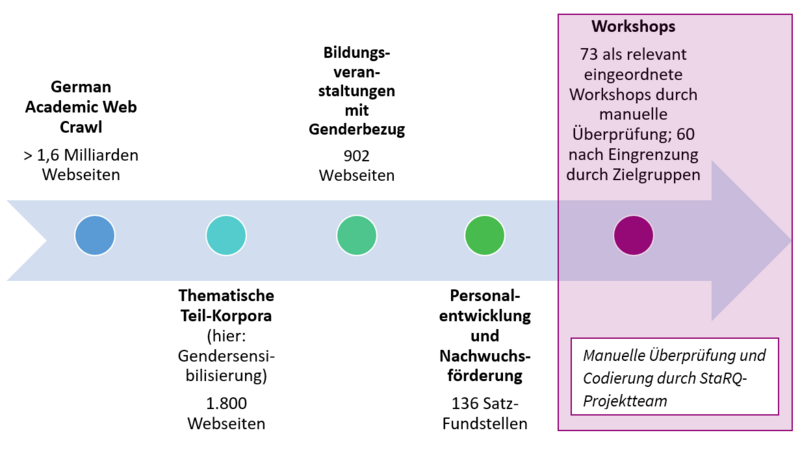
Abbildung 5: Prozessdarstellung von Big Data zu nützlichen Insights
Fazit
Die hier skizzierten Methoden illustrieren das Zusammenspiel von automatisierten und manuellen Verfahren. Sie spiegeln aber auch das Ergebnis eines Lernprozesses wider, bei dem auf der einen Seite die inhaltliche Arbeit sukzessive mehr von automatischen Verfahren profitierte. Und auf der anderen Seite die Auswahl der automatischen Verfahren immer besser an die Bedürfnisse der inhaltlichen Arbeit angepasst wurde. Diese Verschränkung führte in der Konsequenz zu präzisen, verwertbaren Ergebnissen. So konnte nachgezeichnet werden, dass nach wie vor Maßnahmen zu Gendersensibilisierung in erster Linie im Kontext von Studium und Lehre entwickelt und angeboten werden. In Zusammenhang mit Berufungskommissionen werden Gleichstellungsbeauftragte häufiger als andere Mitglieder der Kommission adressiert. Personen mit Leitungsaufgaben hingegen sind generell selten explizit als Zielgruppe von Gendersensibilisierungs-Maßnahmen genannt. Hierbei ist allerdings zu berücksichtigen, dass mit dem Web Crawl nur öffentlich zugängliche Daten untersucht werden können. Um Good Practice transparent zu machen und das gegenseitige Lernen zu fördern, wäre eine Veröffentlichung entsprechender Maßnahmen wünschenswert.
Förderkennzeichen: 01FP1901
![]()